ChatGPT goes to the operating room: evaluating GPT-4 performance and its potential in surgical education and training in the era of large language models
- Affiliations
-
- 1Department of Surgery, Samsung Medical Center, Sungkyunkwan University School of Medicine, Seoul, Korea
- KMID: 2542233
- DOI: http://doi.org/10.4174/astr.2023.104.5.269
Abstract
- Purpose
This study aimed to assess the performance of ChatGPT, specifically the GPT-3.5 and GPT-4 models, in understanding complex surgical clinical information and its potential implications for surgical education and training.
Methods
The dataset comprised 280 questions from the Korean general surgery board exams conducted between 2020 and 2022. Both GPT-3.5 and GPT-4 models were evaluated, and their performances were compared using McNemar test.
Results
GPT-3.5 achieved an overall accuracy of 46.8%, while GPT-4 demonstrated a significant improvement with an overall accuracy of 76.4%, indicating a notable difference in performance between the models (P < 0.001). GPT-4 also exhibited consistent performance across all subspecialties, with accuracy rates ranging from 63.6% to 83.3%.
Conclusion
ChatGPT, particularly GPT-4, demonstrates a remarkable ability to understand complex surgical clinical information, achieving an accuracy rate of 76.4% on the Korean general surgery board exam. However, it is important to recognize the limitations of large language models and ensure that they are used in conjunction with human expertise and judgment.
Figure
-
Fig. 1 (A) Dataset preparation process for model evaluation. (B) How models were evaluated from ChatGPT website.
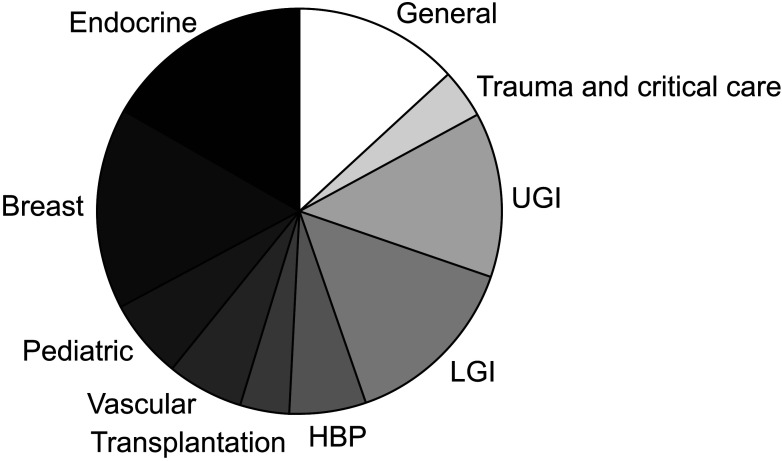
Fig. 2 The dataset was composed of 280 questions, and it is classified into subspecialties in the field of general surgery. HBP, hepatobiliary and pancreas; LGI, lower gastrointestinal; UGI, upper gastrointestinal.
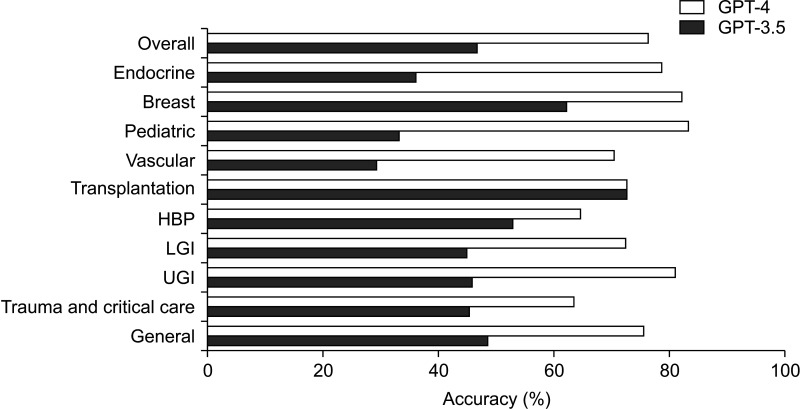
Fig. 3 Comparison of the performance of GPT-4 and GPT-3.5 with overall accuracy and accuracies according to its subspecialties. GPT, generative pretrained transformer; HBP, hepatobiliary and pancreas; LGI, lower gastrointestinal; UGI, upper gastrointestinal
Cited by 1 articles
-
ChatGPT Predicts In-Hospital All-Cause Mortality for Sepsis: In-Context Learning with the Korean Sepsis Alliance Database
Namkee Oh, Won Chul Cha, Jun Hyuk Seo, Seong-Gyu Choi, Jong Man Kim, Chi Ryang Chung, Gee Young Suh, Su Yeon Lee, Dong Kyu Oh, Mi Hyeon Park, Chae-Man Lim, Ryoung-Eun Ko
Healthc Inform Res. 2024;30(3):266-276. doi: 10.4258/hir.2024.30.3.266.
Reference
-
1. OpenAI. Introducing ChatGPT [Internet]. OpenAI;c2015-2023. cited 2023 Feb 10. Available from: https://openai.com/blog/chatgpt .2. Kung TH, Cheatham M, Medenilla A, Sillos C, De Leon L, Elepaño C, et al. Performance of ChatGPT on USMLE: potential for AI-assisted medical education using large language models. PLOS Digit Health. 2023; 2:e0000198. PMID: 36812645.3. Mbakwe AB, Lourentzou I, Celi LA, Mechanic OJ, Dagan A. ChatGPT passing USMLE shines a spotlight on the flaws of medical education. PLOS Digit Health. 2023; 2:e0000205. PMID: 36812618.4. Bommarito M II, Katz DM. GPT takes the Bar Exam [Preprint]. arXiv. 2212.14402. Posted online 2022 Dec 29. Available from: . DOI: 10.48550/arXiv.2212.14402.5. Choi JH, Hickman KE, Monahan A, Schwarcz DB. Chatgpt goes to law school. Minnesota Legal Studies Research Paper No. 23-03 [Internet]. SSRN;2023. cited 2023 Feb 10. Available from: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4335905 .6. Debas HT, Bass BL, Brennan MF, Flynn TC, Folse JR, Freischlag JA, et al. American Surgical Association Blue Ribbon Committee Report on Surgical Education: 2004. Ann Surg. 2005; 241:1–8. PMID: 15621984.7. Wartman SA, Combs CD. Medical education must move from the information age to the age of artificial intelligence. Acad Med. 2018; 93:1107–1109. PMID: 29095704.8. Radford A, Narasimhan K, Salimans T, Sutskever I. Improving language understanding by generative pre-training [Internet]. OpenAI;2018. cited 2023 Feb 10. Available from: https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf .9. Kapadia MR, Kieran K. Being affable, available, and able is not enough: prioritizing surgeon-patient communication. JAMA Surg. 2020; 155:277–278. PMID: 32101264.10. Han ER, Yeo S, Kim MJ, Lee YH, Park KH, Roh H. Medical education trends for future physicians in the era of advanced technology and artificial intelligence: an integrative review. BMC Med Educ. 2019; 19:460. PMID: 31829208.11. Bender EM, Gebru T, Mcmillan-Major A, Shmitchell S. On the dangers of stochastic parrots: can language models be too big? In : FAccT '21: Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency; 2021 Mar 3-10; p. 610–623. Available from: . DOI: 10.1145/3442188.3445922.12. Luo R, Sun L, Xia Y, Qin T, Zhang S, Poon H, et al. BioGPT: generative pre-trained transformer for biomedical text generation and mining. Brief Bioinform. 2022; 23:bbac409. PMID: 36156661.13. Touvron H, Lavril T, Izacard G, Martinet X, Lachaux MA, Lacroix T, et al. Llama: Open and efficient foundation language models. arXiv [Preprint]. 2023; 02. 27. DOI: 10.48550/arXiv.2302.13971.14. OpenAI. GPT-4 technical report [Internet]. Open AI;2023. cited 2023 Feb 10. Available from: https://cdn.openai.com/papers/gpt-4.pdf .
- Full Text Links
-
- Actions
-
Cited
- CITED
-
- Close
- Share
-
- Similar articles
-
- Performance of a Large Language Model in the Generation of Clinical Guidelines for Antibiotic Prophylaxis in Spine Surgery
- ChatGPT’s Potential in Dermatology Knowledge Retrieval: An Analysis Using Korean Dermatology Residency Examination Questions
- Performance of ChatGPT on Solving Orthopedic Board-Style Questions: A Comparative Analysis of ChatGPT 3.5 and ChatGPT 4
- Evaluating the Feasibility of ChatGPT in Dental Morphology Education: A Pilot Study on AI-Assisted Learning in Dental Morphology
- The Integration of Large Language Models Such as ChatGPT in Scientific Writing: Harnessing Potential and Addressing Pitfalls
